controlsBar = () => {
return (
<React.Fragment>
{this.state.fileState===this.fileState.uploaded ? (<Zip addToPreviousUploads={() => this.addToPreviousUploads()} fileName={`${process.env.REACT_APP_IMAGE_BUCKET}${this.state.s3SafeFileName.split('.')[0]}.zip`} />) : null}
<input className='btn btn-success input-padding' value={this.state.fileName} onChange={this.handleChange} ref={(ref) => { this.uploadInput = ref; }} type="file" accept=".pdf"/>
<Button onClick={this.pdfUpload} disabled={!this.state.fileName} className='convert-button-padding'>Convert to JPG Images</Button>
</React.Fragment>
)
}controlsBar contains PdfUpload - A method called right when the user clicks the upload button. Just sets up the states for analysis and eventual upload
pdfUpload = () => {
let file = this.uploadInput.files[0];
let fileParts = this.uploadInput.files[0].name.split('.');
let fileName = fileParts[0];
let fileType = fileParts[1];
this.setState({fileState: this.fileState.analyzing, errorMessage: "", uploadFile:file, s3SafeFileName: `${this.localIdentifier('pcid')}${file.name.replace(/[^0-9a-zA-Z_.]/g, '')}`, uploadFileType:fileType,uploadFileName:fileName})
}controlsbar also contains addToPreviousUploads - the method is called after the zip file is generated and discovered by the app. It is used to persist necessary information about the location of the zip file and images in s3 so it can be recalled later.
We also check here if the file was previously uploaded, and only give it a new ID if it's a new file that wasnt previously uploaded.
addToPreviousUploads = () => {
var prev_uploads = this.props.previous_uploads;
var found = prev_uploads.findIndex((upload) => {
return (upload.uploadFileName === this.state.uploadFileName && upload.numPages === this.state.numPages)
});
if (found === -1) {
prev_uploads.push({uploadFileName: this.state.uploadFileName, numPages: this.state.numPages, s3SafeFileName: this.state.s3SafeFileName})
this.saveLocal('previous_uploads', JSON.stringify(prev_uploads))
}
this.props.previous_uploads_update(found)
}
features is basically a text method that explains app features
features = () => {
return (
<React.Fragment>
<div><img className="image-style" src="/upload.gif" /></div>
<Row>
<Col xs="12" className='center heading-font-plus'>Features</Col>
<Col md="4" className='mt2'><h4>Download a ZIP Archive</h4>
You can download each image individually by clicking on the download button below each image,
or you can download a ZIP file containing all the images.
</Col>
<Col md="4" className='mt2'><h4>Access your previously uploaded PDFs</h4>
Previously uploaded PDFs are will be available to be viewed and downloaded again on the same computer. Images and PDFs and
ZIP files are stored on the server for 30 days before they are erased.
</Col>
<Col md="4" className='mt2'><h4>Full Size Image Viewer</h4>
Click on the image to open the image full size. You'll be able to download, rotate or see an
even bigger version of the image.
</Col>
</Row>
</React.Fragment>
)
}
Methods inside fileStateSwitch
Description is a text only methods that describe the app - this one is displayed in the base state
description = () => {
return (
<div className="main-style">
<Container>
<div className="tight-container">
<div className='center heading-font'>Convert a PDF file to a set of optimized JPG images</div>
<div className="mt2 sub-heading-font">This free tool converts PDFs to JPGs. It shows thumbnails of each page so you can easily enlarge and download only the files you wish to download</div>
<div className="mt2 sub-heading-font">Click the 'Choose File' button and select a PDF file you wish to convert. Click 'Convert to JPG images' and wait for the conversion process to finish.</div>
</div>
</Container>
</div>
)
}
DocumentAnalyze represents our analyze step where we use react-pdf to load the pdf in order to grab our pdf page count
documentAnalize = () => {
return (
<div>
<Document
file={this.uploadInput.files[0] }
onLoadSuccess={this.onDocumentLoad.bind(this)}
>
</Document>
</div>
)
}
onDocumentLoad = ({numPages}) => {
this.setState({ numPages, fileState: this.fileState.uploading });
}
NumPagesDisplay is a display of how many pages the pdf has. We only display this in the intern between when we're generating jpgs
documentAnalize = () => {
return (
<divmentLoad = ({numPages}) => {
this.setState({ numPages, fileState: this.fileState.uploading });
}as for PDFImages and S3Upload, I will explain them in a futher tutorial, but they are available on github
Additional Methods in <Main>
we use the following method to create a random variable to identify the current user. Once we've created the variable, it will be saved in local storage and not recreated if it already exists. It helps us to not only ensure we assign only 1 identifier to a browser, but also keeps a user's file uploads separate, even if the name of their pdf's is the same.
localIdentifier = (id) => {
if (localStorage.getItem(id)) {
return localStorage.getItem(id);
}
else {
var randomNumber = Math.floor(Math.random() * 100000000);
localStorage.setItem(id, randomNumber);
return randomNumber;
}
}
We also have the react life cylce method componentDidMount. We're using it to check if our current url is pointing to a previously uploaded pdf, and loading it if it is actually still present on the server. If were pointing to a route we dont have a file for anymore, we throw an error.
componentDidMount = () => {
const { previous_uploads, params } = this.props;
if ( previous_uploads.length > 0 && this.props.params.index !== undefined) {
let { uploadFileName, numPages, s3SafeFileName} = previous_uploads[params.index];
var imgs = [];
for(var index=1;index <= Math.min(pagesToDisplay,numPages) ;index++){
imgs.push(`${process.env.REACT_APP_IMAGE_BUCKET}${s3SafeFileName.split('.')[0]}/image${index}.jpg`);
}
if (FileStatus(`${process.env.REACT_APP_IMAGE_BUCKET}pdfs/${s3SafeFileName}`)===200) {
this.setState({fileState: this.fileState.uploaded, images: imgs, firstPage: 1, lastPage: Math.min(pagesToDisplay,numPages), uploadFileName, numPages, s3SafeFileName})
} else {
this.setState({errorMessage: "Can't find pdf - server probably deleted it"})
}
}
}
handlePageClick is called on a pagination click. It is called from a sub-component (PDFImages). It sets the images state to the link of the images to be displayed on the clicked on page, and also updates the page numbers on that pagination page
handlePageClick = data => {
let offset = data.selected * pagesToDisplay;
var imgs = []
for(var index=1+offset;index <= Math.min(pagesToDisplay+offset,this.state.numPages); index++){
imgs.push(`${process.env.REACT_APP_IMAGE_BUCKET}${this.state.s3SafeFileName.split('.')[0]}/image${index}.jpg`);
}
this.setState({images: imgs, firstPage: 1+offset, lastPage: Math.min(pagesToDisplay+offset,this.state.numPages)})
}
the saveLocal method just a wrapper around our current local storage implementation, in case change it in the future.
saveLocal = (id,prev_uploads) => {
localStorage.setItem(id,prev_uploads)
}
setToSuccess - the method our s3 uploader calls to set the states after our upload is complete (this will trigger our backend function with an s3 hook, and we can load our image frames, but we will still have to display a loader while our backend does its work)
setToSuccess = (imgs) => {
this.setState({fileState: this.fileState.uploaded, images: imgs, firstPage: 1, lastPage: Math.min(pagesToDisplay,this.state.numPages)});
}
Handle change - A method used for setting the state after the user selects a pdf (used to display the name of the selected pdf)
handleChange = (ev) => {
this.setState({fileName : ev.target.value});
}
I may have a follow up tutorial explaining the smaller components, but for now you can just reference them on the app's github repo.

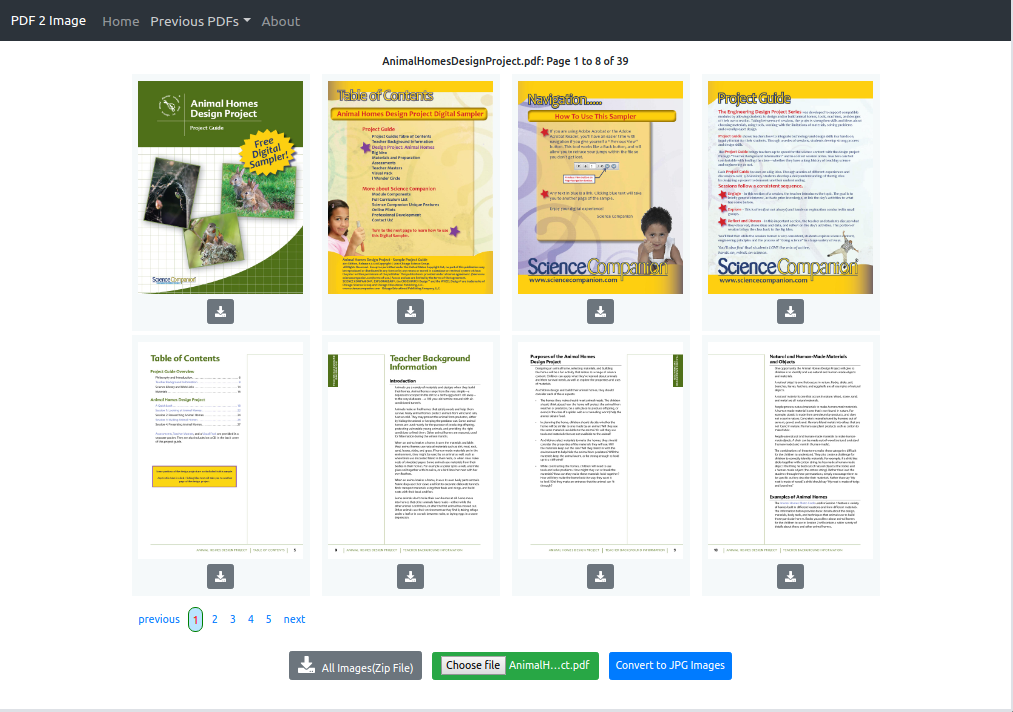
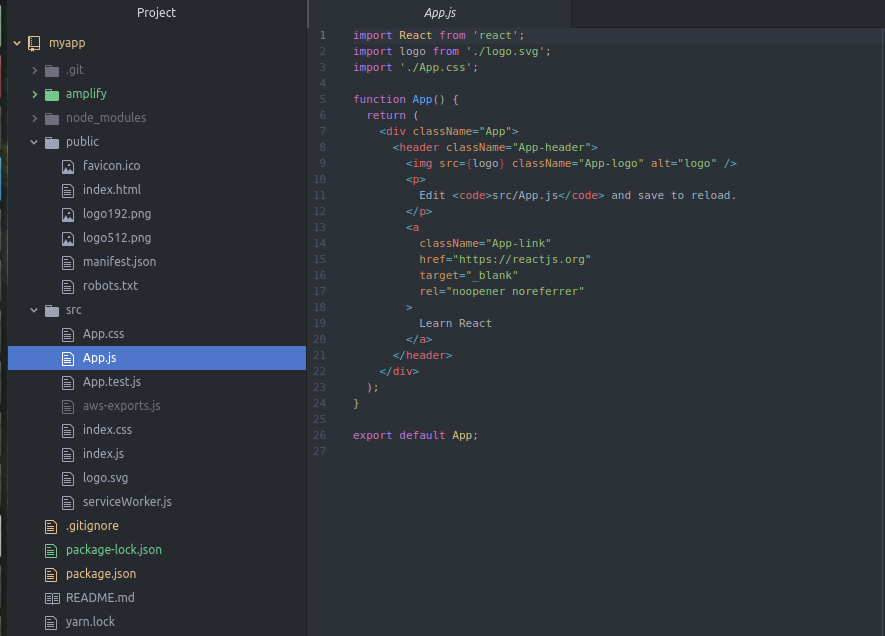
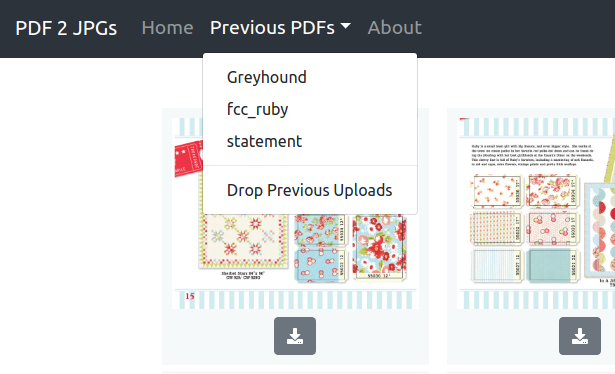


 Posted by Jonathan Weyermann on December 6, 2019 at 12:12 AM
Posted by Jonathan Weyermann on December 6, 2019 at 12:12 AM



9 Comments
ieprzgibnsMay 25 2021 at 6:38 PM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann <a href="http://www.gyn7x40j9uqu124ik575u69v52tt35sqs.org/">aieprzgibns</a> ieprzgibns http://www.gyn7x40j9uqu124ik575u69v52tt35sqs.org/ [url=http://www.gyn7x40j9uqu124ik575u69v52tt35sqs.org/]uieprzgibns[/url]xxkfijvmSeptember 20 2021 at 3:53 AM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann <a href="http://www.g4z9y0j21hwwz53zv3rxw5br961o7176s.org/">axxkfijvm</a> [url=http://www.g4z9y0j21hwwz53zv3rxw5br961o7176s.org/]uxxkfijvm[/url] xxkfijvm http://www.g4z9y0j21hwwz53zv3rxw5br961o7176s.org/cnlgxerzjOctober 27 2021 at 10:19 AM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann <a href="http://www.g9u9m0945s16e34z3yrj2j901wkysxv6s.org/">acnlgxerzj</a> cnlgxerzj http://www.g9u9m0945s16e34z3yrj2j901wkysxv6s.org/ [url=http://www.g9u9m0945s16e34z3yrj2j901wkysxv6s.org/]ucnlgxerzj[/url]kmzinfntsxOctober 31 2021 at 3:54 AM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann kmzinfntsx http://www.g5zewx48z94vh2c6235v5xgsh279pd29s.org/ [url=http://www.g5zewx48z94vh2c6235v5xgsh279pd29s.org/]ukmzinfntsx[/url] <a href="http://www.g5zewx48z94vh2c6235v5xgsh279pd29s.org/">akmzinfntsx</a>qlggirceytDecember 24 2021 at 11:11 AM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann [url=http://www.g623h31rxz44wpmpm07m666uq32tn24ws.org/]uqlggirceyt[/url] qlggirceyt http://www.g623h31rxz44wpmpm07m666uq32tn24ws.org/ <a href="http://www.g623h31rxz44wpmpm07m666uq32tn24ws.org/">aqlggirceyt</a>qddkbpnMay 20 2022 at 2:23 AM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann qddkbpn http://www.gn9qk852j24m2j9xf30914oy9w1qwo1vs.org/ <a href="http://www.gn9qk852j24m2j9xf30914oy9w1qwo1vs.org/">aqddkbpn</a> [url=http://www.gn9qk852j24m2j9xf30914oy9w1qwo1vs.org/]uqddkbpn[/url]bjhnynpAugust 7 2022 at 5:21 AM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann [url=http://www.g2l1qr40o15lzjh5457zsdv75q4u4j68s.org/]ubjhnynp[/url] bjhnynp http://www.g2l1qr40o15lzjh5457zsdv75q4u4j68s.org/ <a href="http://www.g2l1qr40o15lzjh5457zsdv75q4u4j68s.org/">abjhnynp</a>eehvewclwJanuary 21 2024 at 12:36 PM
Creating a PDF conversion tool using Serverless and Amplify - Part 1 - React App - Jonathan Weyermann <a href="http://www.gl1etmi47095ciz2khd34in5l90b7025s.org/">aeehvewclw</a> eehvewclw http://www.gl1etmi47095ciz2khd34in5l90b7025s.org/ [url=http://www.gl1etmi47095ciz2khd34in5l90b7025s.org/]ueehvewclw[/url][email protected]June 21 2024 at 5:20 AM
iste in laboriosam aut vitae maiores dolor ex id quibusdam. doloribus in dicta et odit quidem reiciendis saepe debitis facilis pariatur ut ut sequi laboriosam quam. labore perspiciatis consectetur rerum odio illum delectus. animi quod facilis nam culpa libero consequatur velit quia earum nostrum et iusto ad recusandae odio libero. natus eum iure qui qui aut molestiae quos sequi voluptatem qui alias voluptatem eveniet quia ex.Replying to comment kmzinfntsxOctober 31 2021 at 3:54 AM